The insurance industry is an important part of the national financial development and is related to the well-being of the country and its people, bearing the social responsibility of safeguarding the property and personal safety of the citizens.
With the continuous growth and development of the domestic insurance industry, the main model of the industry has become diversified, with insurance groups taking the lead. Major insurance groups are showing a trend towards diversified development, establishing subsidiary companies to achieve specialized operations while building on the coordination and development of the parent company. A large insurance group often establishes subsidiary companies for property insurance, life insurance, health insurance, and pension insurance, achieving refined and specialized management.
In the wave of digital transformation, both the group and its subsidiary companies are implementing a series of customized digital strategies according to their respective development needs.
As a well-established enterprise in the field of data management, DSI has been deeply involved in the industry for over twenty years and has established close cooperative relationships with many insurance companies. Taking a large insurance group and its subsidiaries for property insurance, life insurance, and health insurance as an example, DSI has actively participated in the digital upgrading process of the group and its subsidiary companies through customized solutions.
01 Insurance Group - Data Lake Entry and Migration Synchronization
Group: Data Lake Entry + Migration Synchronization
Adopting a unique technical route involving multiple big data components.
Full data synchronization: Source Database-Hive-Hudi
Incremental data synchronization: Source Database-Kafka-Spark-Hudi
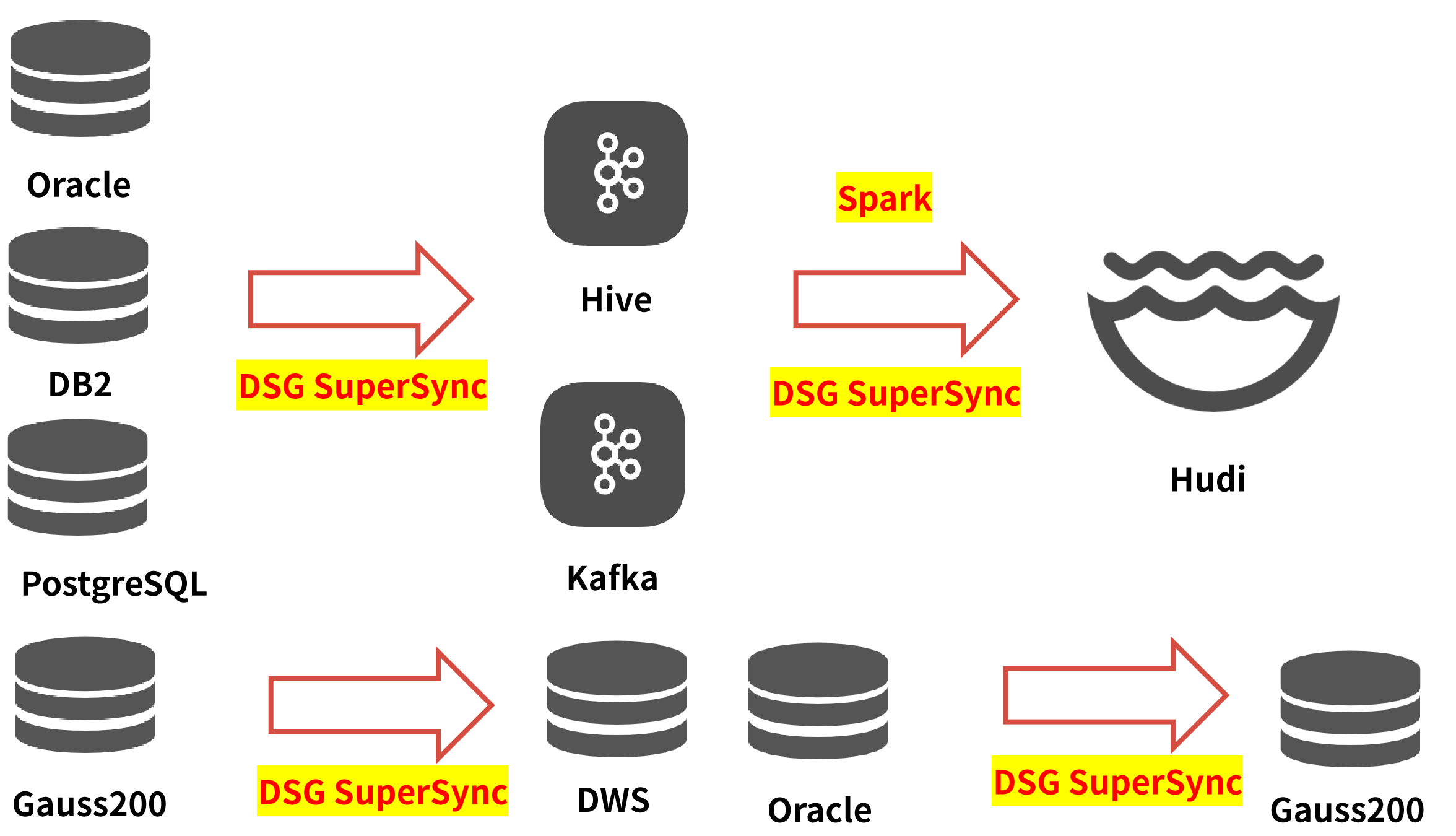
The group coordinates the various subsidiaries and has the authority to make major decisions. With the continuous increase in data volume, the existing environment is no longer able to meet the production needs. Therefore, the insurance group has proposed a data lake solution, in which the data from its various subsidiaries is synchronized from the source repository to Hudi, while the data required by downstream applications is migrated from Gauss200 to DWS.
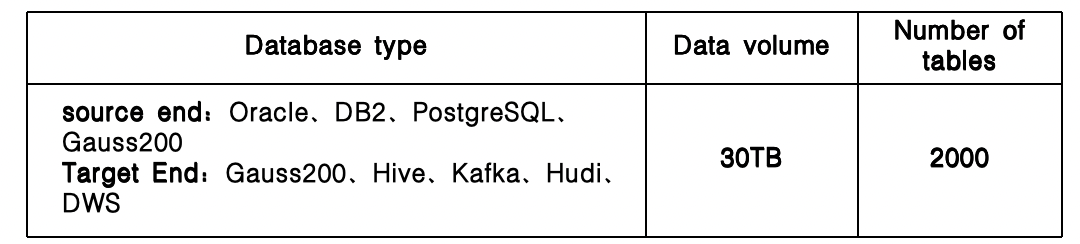
This digitalization project involves the systems of three subsidiary companies in the life insurance, health insurance, and pension insurance sectors. There are multiple source endpoints, multiple software queues, and a large maintenance workload. It is necessary to collect data from the subsidiary companies (life insurance, health insurance, and pension insurance) and standardize and analyze the data.
Throughout the entire data lake project, DSG SuperSync, a high-performance replication tool for large databases, provides full support for data synchronization, data migration, and ETL (adding, deleting, and modifying columns) scenarios.
In the project, DSG adopts a deployment mode using an intermediate machine and opens up a unique technical route through innovative technical solutions. Using Hive and Kafka as temporary storage components for full and incremental data, and later using Spark engine (a fast, general-purpose computing engine designed for large-scale data processing) to improve the efficiency of data processing (into Hudi), efficient data transmission across the north and south data centers has been achieved.
DSG fully leverages its professional expertise, conducting independent research and development, and custom development to modify and adapt tools for writing to Hive and Kafka. A new Hudi program for data lake ingestion has been developed to ensure a perfect fit with the solution and project requirements.
02 Property Insurance - Data Synchronization and Migration
Property Insurance: Data synchronization, data migration
One-to-one, one-to-many, many-to-one, and many-to-many data synchronization and migration for multiple systems.
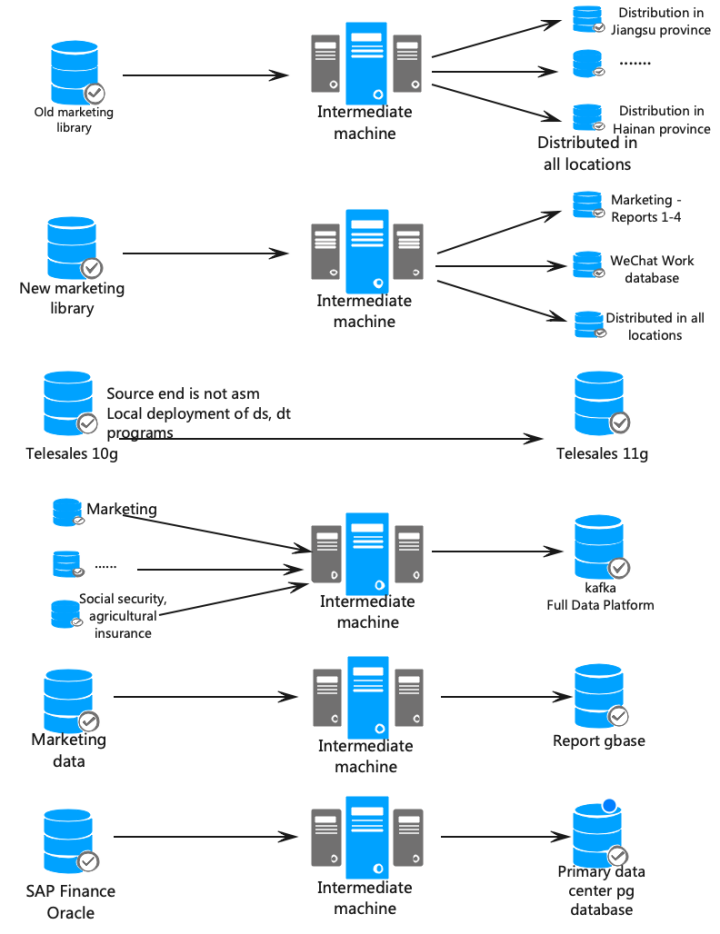
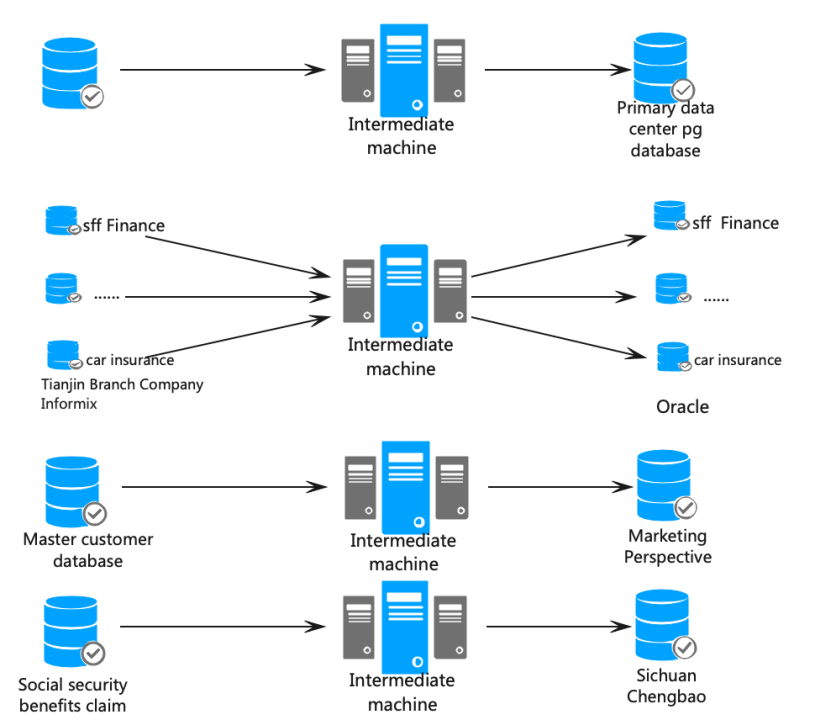
Property and casualty insurance companies are primarily responsible for compensating for property losses, with a wide range of business coverage and strong IT system complexity, and intricate internal data flows. To adapt to the system updates and replacements brought about by business development, there are various demands for one-to-one, one-to-many, many-to-one, and many-to-many data synchronization.

The marketing system, as the core system for the development of property insurance business, is the focus of this digital implementation. The marketing database is cleared to various municipal and provincial levels using the DSG SuperSync large database high-performance replication tool; the data business switch hardware upgrade for the marketing database-new marketing system to distribute the pressure; multi-level synchronization of data from the marketing system to various subordinate reporting systems; marketing system consuming full data platform data on the big data platform Kafka, providing users with viewing capabilities and more. In addition, real-time synchronization operations were performed on the data of agricultural insurance, social security, claims and other systems, and database migration was carried out in collaboration with customers, with positive and reverse synchronization for switching.
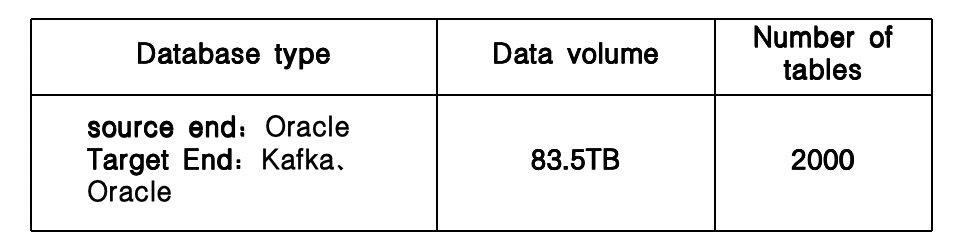
For property insurance enterprises, there are multiple types and multiple points of target end, and a large amount of maintenance due to the numerous channels. In addition, special handling and compatibility conversion are required for different field types among multiple databases. The data clearing to various localities in the marketing is complex and involves multiple filtering conditions based on table configurations. The conversion and replacement of data (such as spaces, quotation marks, etc.) from the marketing database to the Kafka big data platform is complex in terms of data situations and required processing logic. The distributed databases such as Gbase and Tbase need to consider factors such as nodes, table-level locks, and connection limits, and flexible changes in software configuration are required to adapt to various complex environments. The migration of TB-level daily archive data with a total of 50TB data and over ten thousand tables poses obvious application difficulties.
03 Life Insurance-Heterogeneous Replication and Collection Exchange
Life insurance: Heterogeneous replication + collection exchange
Replacement of a well-known replication product to meet the needs of multiple scenarios.
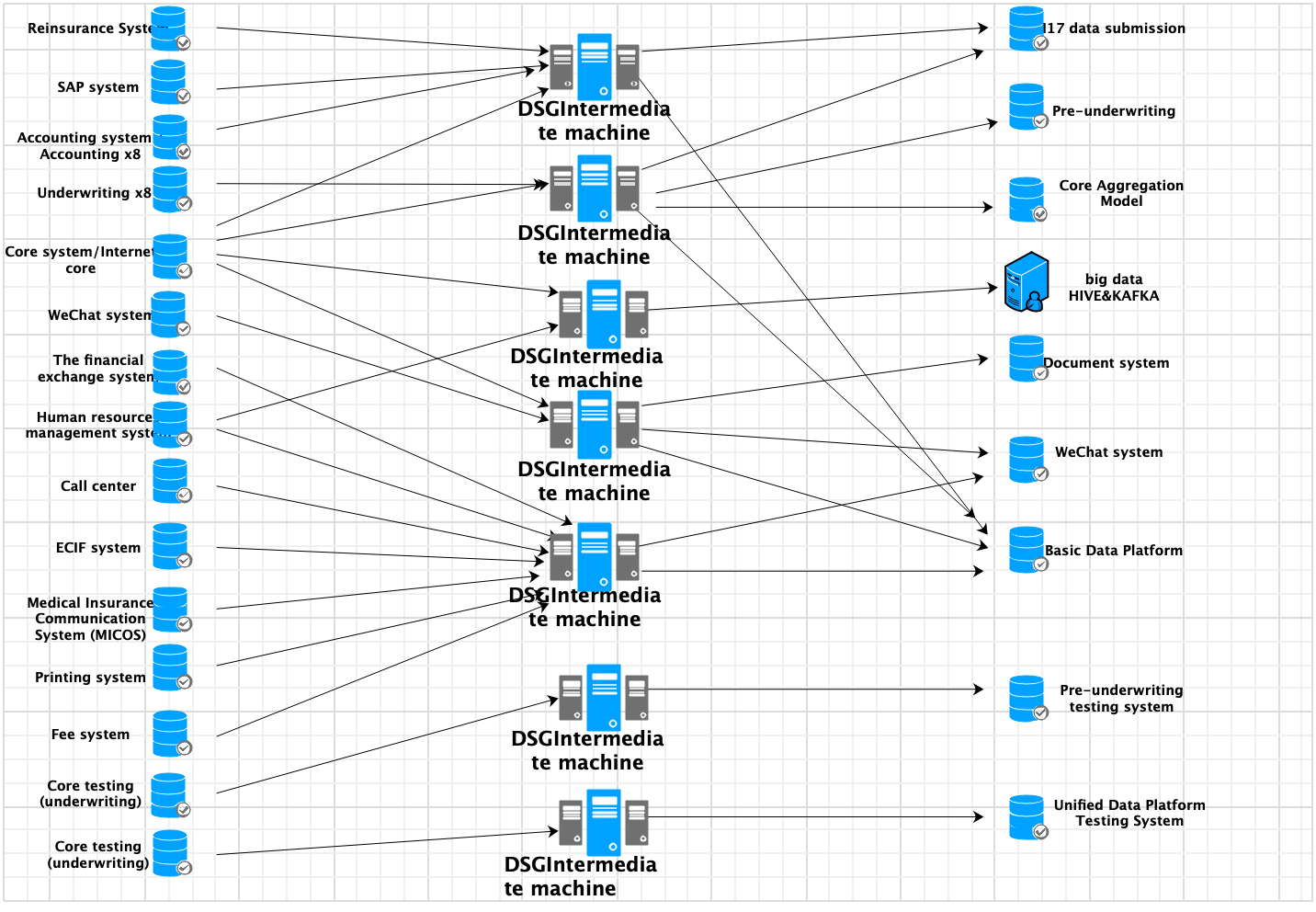
As the life insurance business data grows, the timeliness requirements increase, and new systems such as big data platforms require heterogeneous replication, the original well-known replication product data replication can no longer meet the life insurance on-site replication requirements. Therefore, the DSG data replication scheme is adopted to replace the replication product, ensuring data synchronization and collection exchange requirements.
During the project, DSG achieves the replacement of the replicated product and ensures the consistency and real-time data through the initialization and breakpoint resume modes. Different modes and configurations are used for normal tables, compressed tables, and tables without primary keys to ensure the consistency of data loading. For ETL operations with differences between the source and target ends, analysis delays caused by DSG libraries exceeding 24 hours, and issues with compressed table differences, DSG has implemented effective measures to achieve satisfactory results.
DSG's data replication solution provides quasi-real-time data services for multiple systems such as life insurance basic data platforms, underwriting front-end systems, single document systems, WeChat systems, core aggregation models, big data platforms, and 117 data reporting platforms.
By deploying the DSG DataXone data collection and sharing exchange platform, the project can achieve:
These functions collectively improve data quality, ensuring the integrity, accuracy, consistency, and timeliness of data replication in various systems.
04 Health Insurance - Localization and Cloud Migration
Health Insurance: Localization and Cloud Migration
Synchronization of data between new and old core systems in high-risk flows, as well as migration of data to the cloud.
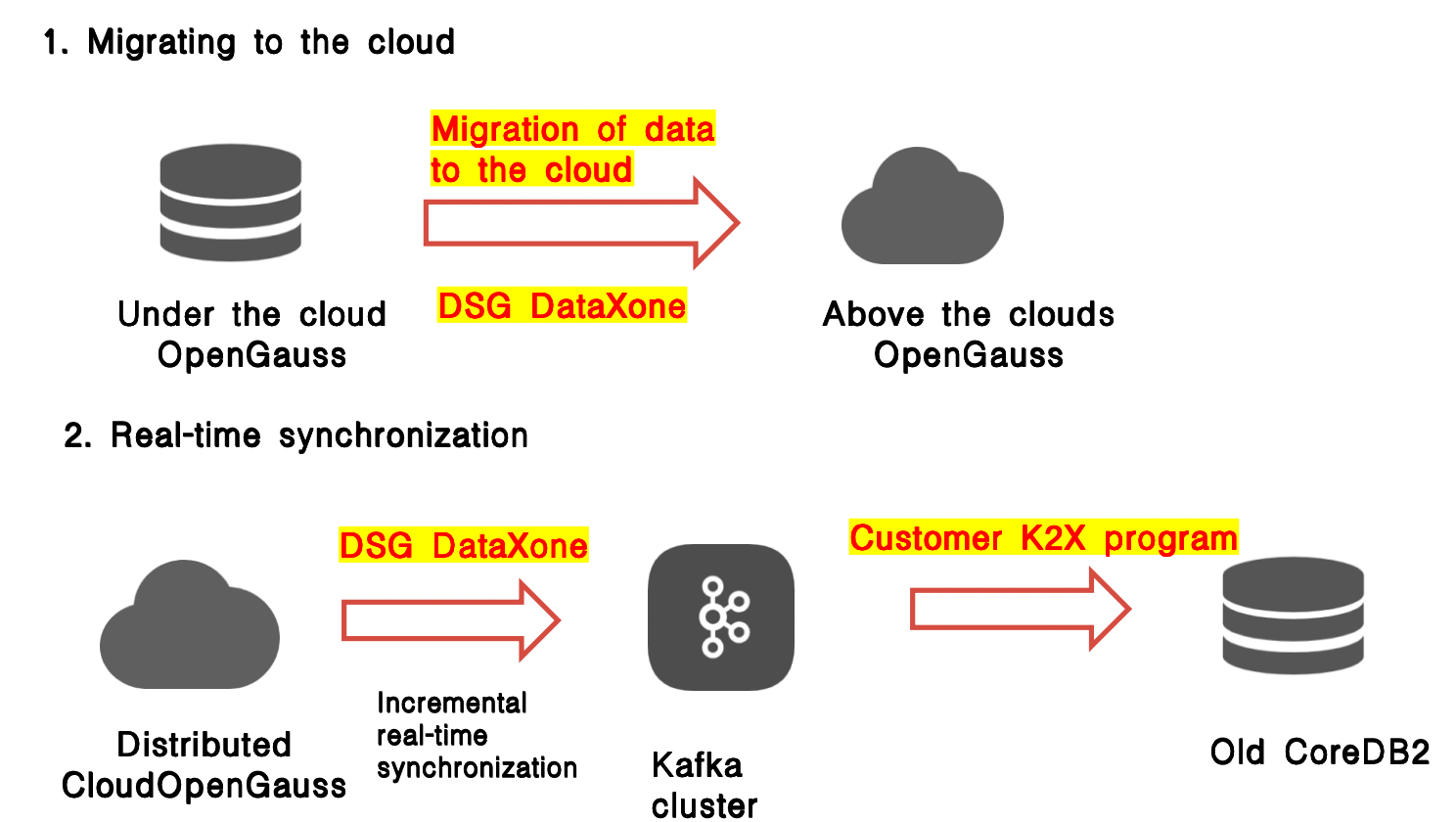
Driven by the trend of localization, the core system of health insurance companies will store new business data in the domestic database OpenGauss, while the old core system data is on DB2. In order for the new and old core systems to coexist, the newly added data on the new core system needs to be processed and synchronized to the old core system. At the same time, in order to facilitate the unified management of servers and databases, the company plans to migrate all existing OpenGauss database data from the on-premises cloud to the cloud-based OpenGauss database, gradually replacing the on-premises environment.

This data synchronization uses Kafka as the middleware. Through the DSG DataXone data collection and sharing exchange platform, incremental data is synchronized from the OpenGauss database to Kafka, and then the client's k2x program sinks the data from Kafka into the old core DB2.
This project scenario represents a high-risk flow direction. Once a problem occurs leading to data loss, it is difficult to recover the lost data. Fortunately, DSIJ relies on independent research and development. Faced with the particularity of the synchronization flow from OpenGauss to Kafka and the slot export mode of the OpenGauss database, they have developed an adaptation of the Kafka message format for Huawei DRS, ensuring that the data format and column values are completely consistent, optimizing product tools, and ensuring smooth synchronization.
In addition, DSG DataXone provides full support for cloud data migration of OpenGauss, as the volume of application data continues to grow.
It is foreseeable that the digital construction of the insurance group and its subsidiaries has its own merits and is also filled with thorns. Nevertheless, with our powerful digital solutions, we are able to assist them in effectively addressing challenges and achieving business upgrades and transformation.
In the future, DSIJ will take greater strides on the road of digital transformation services, providing customers with more comprehensive, high-quality, and efficient service solutions, overcoming all obstacles in the way.
2024.05.16
Learn more>
2024.04.01
Learn more>
2024.03.25
Learn more>
2024.03.18
Learn more>
2024.03.04
Learn more>
2024.02.19
Learn more>
2024.02.04
Learn more>
2024.01.22
Learn more>
2024.01.15
Learn more>
2024.01.02
Learn more>
2023.12.25
Learn more>
2023.12.20
Learn more>
2023.12.11
Learn more>
2023.12.04
Learn more>
2023.11.20
Learn more>
2023.11.13
Learn more>
2023.11.06
Learn more>
2023.10.30
Learn more>
2023.10.11
Learn more>
2023.09.15
Learn more>
2023.08.01
Learn more>
2023.07.25
Learn more>
2023.07.04
Learn more>
2023.05.29
Learn more>
2023.05.08
Learn more>
2023.03.06
Learn more>
2022.12.28
Learn more>
2022.11.14
Learn more>
2022.09.26
Learn more>